
I'm sure the biggest background jobs that are running on your live system are important and they get a job done that plays a big part in the system's overall function. Prices need to be (re)calculated, stocks need to be adjusted, an outbound interface on material data needs to be completed. The coding for these - big boys - has been optimized, the performance is tuned and there's is not much more that can be done from a technical viewpoint. Consider using a processing queue.
Processing from a queue
An example: a price-recalculation needs to be done for 500.000 materials. The report that will do this holds customer specific logic and some additional steps that are required. 10 materials are processed each second, however we notice an increase when processing more than 1.000 materials. The functionality that a processing queue provides is simply managing a series of calls to the report. To do this, the report will need to have a select option field in which the material number can be specified.
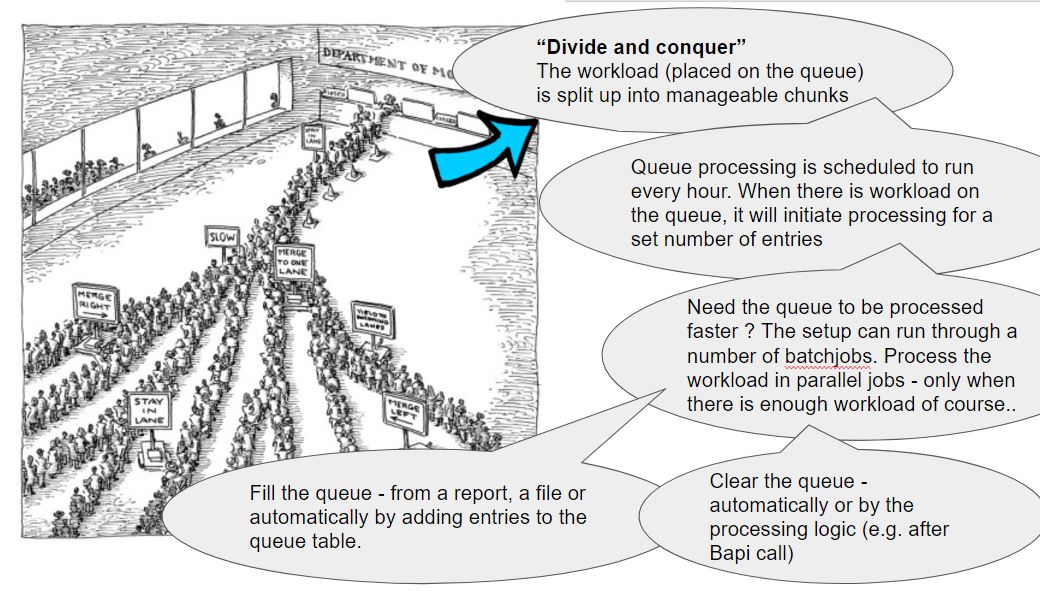
Why process from a queue ? There's a handful of reasons that should make queue processing interesting. The first is a simple fact that large jobs can become slower the longer they run. When the workload is split up into manageable chunks, processing speeds are increased. Another nice side effect of splitting workload is the fact that the chunks can be processed in parallel. So instead of a single report performing all the work, the report can be scheduled multiple times. Another very real side effect of working with processing queues is avoiding peaks. Controlling the workload of large jobs is effectively controlling large jobs.
So what does "the queue" do ?
The queue report (for which the source code is available on this article) is to be scheduled regularly. It checks whether there is work to be done and processes it. Step-by-step:
- (preparation) gather work. The queue is to be filled with key-elements, such as material numbers. This can be done by selection, from a file or from a preparation process (Abap logic)
- (the scheduled job) prepare a processing run, with part of the gathered work. To do this, a variant on the large job (target report) is copied and the material numbers on this variant are filled in
- schedule the processing run (or runs) - thus the scheduled job will itself schedule jobs
- keep scheduling and executing runs until the queue is empty
- (ad hoc intervention - by you) monitor progress by viewing the status tab on the queue report
With this tooling you can fine-tune the major tasks that needs to be executed. You could e.g. schedule the queue to run with 4 parallel tasks for large amounts early in the morning and with only 1 batchjob and smaller amounts during the workday. Monitor the progress on the queue and check whether it gets processed and how long it takes to finish. Adjust processing amounts, number of background jobs and frequency to requirements. Is there a peak ? Instead of the system taking the blow, the queue capture it. SAP's event queue (workflow) is based on the same principle: stay alive, capture peaks.
How does that look ?
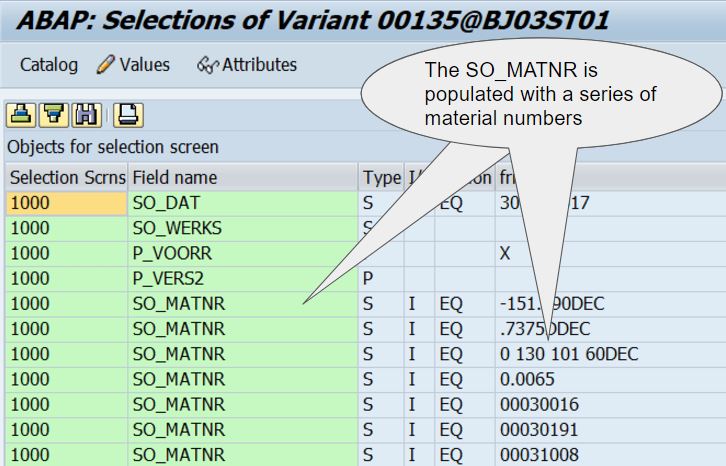
Just to demonstrate what the queue processor does: it copies a variant and populates a (one) key field with values. In the example case the key field is a material number. A series of variants is created to cover a run (or multiple parallel jobs of a run:).

When you have a closer look at one of these variants, you will see which (in this case) materials the variant is prepared for:
Automatically fill the queue
It's a nice feature that the queue can be filled from a selection screen, or even from a file. But the system should really take care of populating new entries for the queue by itself. Here's how: the setup has a method that can be called to place new queue entries in the queue table. You could simply place them on the queue yourselves, but working through the method is better and easier.
data: lv_materials type string.
lv_materials = 'MAT-A;MAT-B;MAT-123'.
CALL METHOD ('\PROGRAM=ZABAPCADABRA_QUEUE_MATERIALS\CLASS=LCL_QUEUE_MANAGER')
=>('QUEUE_FILL_FROM_STRING')
EXPORTING queuekeys =lv_materials.
Make sure you get all the details correct, the main program is called ZABAPCADABRA_QUEUE_MATERIALS, the rest should be as above, unless you altered class names, method names or parameter names.
If you want to set "priority" to the entries you are processing, simply add parameter PRIORITY = ABAP_TRUE to the parameter list.
The life of a queue entry
The queue processor is filled with entries and entries are processed. There's 2 ways of removing entries from the queue:
- Before the selection screen settings on the queue report have a setting that instructs the queue processor to remove entries from the queue the moment they are specified on a variant and ready to be run
- After this option involves a bit of extra Abap coding - in the target program. Let's say a price calculation is done and the results are stored somewhere, and the queue processor is involved to control the runs. After the price calculation was successful, the queue entry is removed. This implies that if no price calculation has taken place (for whichever reason), the material will remain on the queue, to be reprocessed in the next queue round.
That's the level of control that can be captured in queued processing.
Get started with your queue
This article holds 2 source codes:
(1) the queue manager, an include which holds macro definitions and class definitions and implementations for the main program and
 .
.
(2) the main program, which is set up for material numbers. The idea is that you transform this setup to other objects, such as an employee number or a vendor number.
.
If I would have to do so myself, the alternate versions will also be made available here.
What you need first: is a queue table, which holds the following fields:
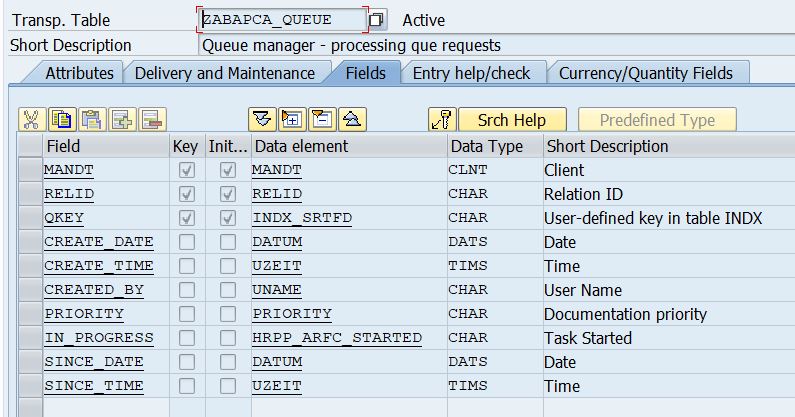
Table name: ZABAPCA_QUEUE |
|
| Description: Queue manager - processing queue requests | |
MANDT RELID QKEY CREATE_DATE CREATE_TIME CREATED_BY PRIORITY IN_PROGRESS SINCE_DATE SINCE_TIME |
MANDT RELID INDX_SRTFD DATUM UZEIT UNAME PRIORITY HRPP_ARFC_STARTED DATUM UZEIT |